
[패턴인식] 패턴인식 소개
패턴 인식 개요
패턴 인식은 이미 알고 있는 것을 인지(또는 분류)하는 과정이다.
사람과 동물의 인식 기능은 robust(강건)하며, 기계도 인식을 할 수 있다.
패턴 인식에 대한 과학적 접근
- 뇌의 정보 처리: 뇌의 정보 처리 과정에 대한 이해를 바탕으로 한다.
- 신경망 연구: 인공지능 및 머신러닝 분야의 핵심적 요소이다.
패턴 인식에 대한 공학적 접근
기존 제품에 인식 기능을 추가하여 부가 가치를 높일 수 있다.
예시:
- 우편물 분류기
- 지문 인식 마우스
- 과속 단속기
패턴 인식의 예시
특징
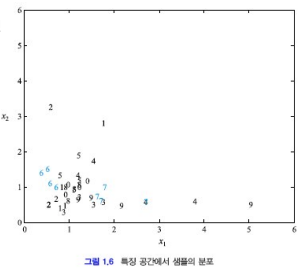
사람의 얼굴에 대한 샘플들은 얼굴 크기(x1), 코의 모양(x2) 등으로 특징을 나타낸다.
분류
특징을 기반으로 확률적 의사결정을 통해 분류한다.
데이터베이스 수집
샘플들은 훈련 셋과 테스트 셋으로 분류된다.
- Train set
- Validation set
- Test set
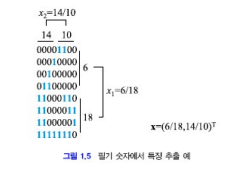
필기 숫자 인식 예시 (LeNet, 2000년대)
- 64개의 화소로 숫자를 표현한다.
- 상/하, 좌/우로 1의 개수를 비교하여 특징 벡터로 분류한다.
특징 벡터들은 서로 멀리 떨어져 구분되어야 하지만, 밀집되면 분류가 어려워져 인식 성능이 저하된다.
이유: 잘못된 Feature가 선택된 경우 분류가 안될 수 있다.
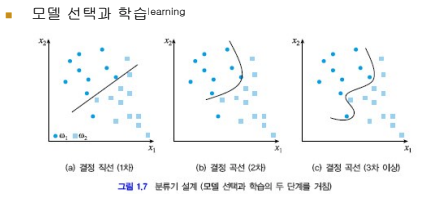
분류 모델
모델의 선택과 학습이 중요하다.
- 좋은 분류기: (b)
- 과적합(Overfitting): (c)
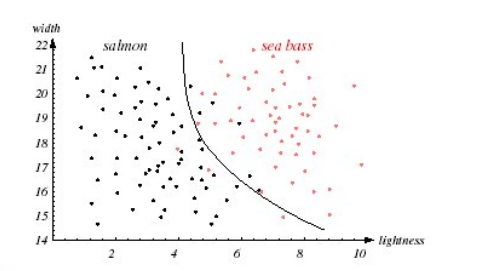
연어 vs 농어 분류 문제
연어와 농어의 이미지를 segmentation한 후 샘플들을 통해 training하여 연어인지 농어인지 분류하는 문제이다.
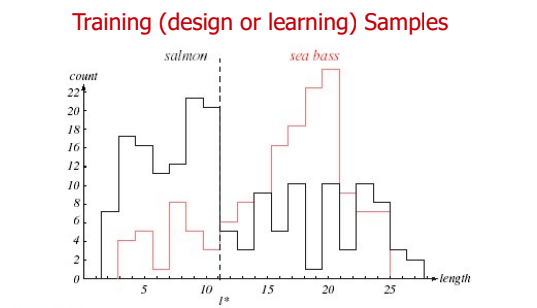
- Length Feature: 길이가 길수록 sea bass인 카운트가 많아져 sea bass로 분류할 수 있다.
- ( l^* ): Decision point로, 이 지점의 위치에 따라 연어인지 농어인지 판단하는 기준이다.
- Decision point에 의해 잘못 분류되는 경우는 error case이다.
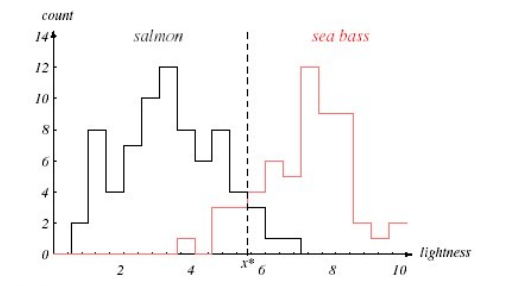
두 번째로는 lightness Feature로 분류된 결과이다.
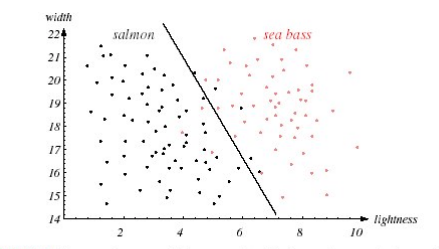
- Linear Decision Boundary: 단순한 경우에는 문제가 없다.
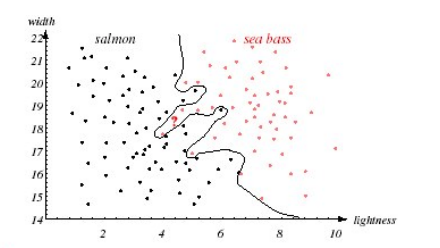
너무 복잡한 decision boundary, Feature vector의 차원이 필요 이상으로 많아지는 경우 -> 과적합(Overfitting) 발생, 다른 문제에서 성능이 저하될 수 있다.
2차 곡선의 decision boundary가 적합한 경우이다.
Simple decision boundaries are preferred.
성능 평가
- TP: True Positive (올바른 정답값 예측)
- FP: False Positive (잘못된 값 예측)
- TN: True Negative (정답이 아닌 것을 예측하지 않은 경우)
- FN: False Negative (정답값을 예측하지 못한 경우)
혼동 행렬 Confusion matrix
두 클래스 w1, w2로 분류하는 문제라고 가정한다면, 2 by 2 행렬의 각 원소 nij는 wi를 wj로 분류한 경우로 표현된다.
| Class | w1 | w2 |
|---|---|---|
| w1 | n11 | n12 |
| w2 | n21 | n22 |
얼굴 검출의 예시
얼굴 검출을 예로 보면 아래와 같이 정리할 수 있다.
- 얼굴을 배경으로 잘 못 검출한 경우 FN (거짓 부정)
- 배경을 얼굴로 잘 못 검출한 경우 FP (거짓 긍정)
- 얼굴을 얼굴로 올바르게 검출한 경우 TP (참 긍정)
- 배경을 배경으로 올바르게 검출한 경우 TF (참 부정)
| 실제 얼굴 (Positive) | 실제 배경 (Negative) | |
|---|---|---|
| 예측 얼굴 | TP (True Positive) | FP (False Positive) |
| 예측 배경 | FN (False Negative) | TN (True Negative) |
성능 지표
- Precision: $ \frac{TP}{TP + FP} $
- Recall: $ \frac{TP}{TP + FN} $
일반화
패턴 인식기의 테스트 집합에 대한 성능을 측정해야 한다 (테스트 셋은 인식기가 한 번도 접하지 못한 샘플들이다).
과적합(Overfitting)을 피해야 한다.
너무 복잡한 모델은 좋지 않다 -> 단순한 인식기가 더 선호된다.
Validation set: 과적합 방지
k-fold cross validation
Resampling (bootstrap)
인식기 학습
- 지도 학습: Classification - Training samples are labeled
- 비지도 학습: Clustering - Training samples are unlabeled
인식의 어려움
- Intra-class Variability: 서로 변화가 크면 분류 작업이 어렵다.
같은 클래스 내에서는 서로 변화가 적어야함. - Inter-class Similarity: 서로 변화가 작으면 분류 작업이 어렵다.
다른 클래스끼리는 서로 변화가 커야함.
UCI Repository
데이터 베이스 특성을 조사
URL : https://archive.ics.uci.edu/ 부류 수, 특징 수, 샘플 수
- Iris
- Letter
- Wdbc
- Segmentation
- Lonosphere